Since almost 4 years the Dual-Write framework is being actively used in D365 for near-real-time data synchronization between Dataverse (customer engagement apps, CE) and Finance and Operations apps (FO). The framework is an evolution of CDS (common data service) integration features and provides bidirectional integration incl. the DELETE action. Along with high number of standard mappings available out of the box Dual-Write provides the possibility of customization and development, following the no-code / low-code principle.
In the current article I would like to present some tricks from the practical perspective of work with Dual-Write. First two tricks concern mapping customizations, and the third trick concerns the initial sync scenario between Dataverse and FO.
Trick #1: General Dual-Write pattern is, that the two entities (from CE and FO) set up in a mapping are both
- either company specific
- or cross-company.
The other pattern when the condition is not met (one entity is company specific and another is cross-company) is not supported. When trying to implement this pattern, by saving the mapping one gets the error: Project validation failed. [DIPV1002] <FO entity> or AX is a cross-company entity that doesn't have primary company field set and <CE entity> of CRM is a company-specific entity with primaryCompanyField set to msdyn_company.cdm_companycode. Please make sure the entities are both cross-company or company-specific entities.
One possible workaround here would be to introduce an intermediate entity for Dual-Write mapping complied with the above pattern and organize data transfer between this intermediate entity and the destination entity.
Trick #2: Let’s consider live sync scenario in the direction FO -> Dataverse. When we have a more complex custom entity with a field related to another FO entity used in another running Dual-Write mapping, a relationship between these two entities must be implemented. The reason for that is, that Dual-Write synchronization (data creation and sending) of related entities occurs in batches. Missing relationships induces multiple batches, which can’t be automatically executed in the correct sequential order, ending up in the run time error: Unable to write data to an entity. Unable to lookup with values {...}. Unable to look up <> with values {...}. Writes to failed with error message Exception message: The remote server returned an error: (400) Bad Request.
An example (custom scenario): creating an employee in FO and synchronizing it via a new custom Dual-Write mapping. When we will add a fully new custom entity containing the field party Id, there must be a relationship linking our custom entity and the standard entity DirPartyCDSEntity from global address book solution. Without this relationship there will be a run-time error (above), indicating, that the new (automatically) created party doesn’t exist. This is obviously not the case (a party is created automatically by creation of a new employee), but Dual-Write live sync of new party id (standard) and the employee (our custom entity) occur in different batches. Just in a scenario when one provides an existing party by creating a new employee, the Dual-Write sync will work in the entity without relationship. Implementing relationships to other entities is a general approach to avoid run time batch synchronization errors.
Standard FO entities, used in standard Dual-Write mappings demonstrate such relationships:
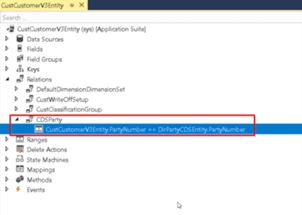
Trick #3 It is well known that Dual-Write synchronization has two modes: live sync and initial sync. When performing initial sync (which is a manual action), one must choose between two options for the master, denoting direction of the desired synchronization: from FO to Dataverse or from Dataverse to FO.

This means, that data will be synchronized from the master to the “opposite side”. It looks logical and is officially documented, but when one checks the Dual-Write logs, one will find out an additional not-documented step. So, the synchronization from master to the “opposite side” is just a first step in the procedure performed by Dual-Write. Following the first step, there will be also a second step, which will be also automatically executed. At this step the data will be synchronized in the opposite direction: from “the opposite side” to the master. This seems not logical in the context of master choice and makes the term “master” confusing. After the whole initial sync is complete (both the two steps executed without errors), the master side will also contain data came from the “opposite side” (which was originally not on master side). One can conclude that Dual-Write initial sync denotes a mixed synchronization, denoting that the master side data will be extended by the data from the “opposite side”.
Interesting fact here is, that even if the first step has failed, the second step will be nevertheless executed. In the case, when there will be no critical issues in the second step, as total result we will get data synchronized in the direction opposite to the original manual choice. This can be very confusing and lead to data loss on master side.
Another consideration is that currently there is no standard possibility to manually force initial sync for a particular data entry of an entity of interest. This would be very practical especially for testing and investigation reasons. The existing initial sync synchronization concerns all (corresponding) data entries from source entity.
Links:
https://ariste.info/en/2021/03/develop-custom-data-entities-dual-write
https://www.linkedin.com/pulse/dual-write-framework-do-dont-adnan-samuel
Comments
question about decimal value mapping
Hi.
Great article, full of insights !
I have a question : I've mapped a Dataverse decimal field, and when i do the initial sync, the value synced from the ERP is way bigger (in ERP 3871, and in dataverse 3,871,000,000.00)... Any idea on how to resolve that issue ?
question about decimal value mapping
Hi Sam
Could you please share details concerning your field and the mapping (one can find different field types in Dual-write standard mappings)
Regards
Pavel